Instancing is a technique to render multiple copies of the same mesh with a different transform with a single API call. Good instancing systems are at the core of any game engine. It gives us a way to draw a game scene the most efficiently. It is important to understand that each game is unique, and that is the reason why every engine has its way of doing instancing “right”. For us the big question was and still is: how do we render the entire planet?
Author: Dmytro Pustovoitov Lead Render Programmer


Requirements
Our studio is small and we want to remain small to be able to change directions and iterate fast. It leads to another design requirement that is applied to almost everything we do: the system must be simple and easy to change. “Keep it simple” - is our golden rule.

We are aiming at huge environments (true Earth-size) with dense flora and detailed terrain. The number of instances is expected to be insane. It is not possible to have enough artists to populate the whole Earth, so most of the instances will be generated procedurally or by Machine Learning Agents (ML-agents). We cannot keep the whole world in memory, so everything must be streamable by nature. Depending on the seed of the random generation, the world can look dramatically different. Many classical game development techniques are not possible with such constraints(like lightmaps). Worth mentioning another problem with offline pre-baking: a slow down of art team iteration time.
We used the indirect-draw instancing pipeline for the Prologue tech demo. While on DX11, we used DrawIndexedInstancedIndirect [1]. It provided us with useful knowledge and proved that it is a valid and performant way of doing instancing. But for Melba, we want to extend it beyond what was achieved for the tech demo.


Feature level
Being in the early stage brings us more freedom in what technologies and hardware we make as our baseline. No requirementsto support legacy code and tech also help. We decided to make DX12-level devices our baseline.
Another big decision on an engine level was to use bindless. Bindless means, instead of declaring slots in the shader and binding the data to those slots on the CPU side, we can directly access the resource heap on the GPU and access the resource by using simple indexing into the heap:
// SM 6.5 and earlier:
Texture2D<float4> textures_2d[] : register(t0);
float4 base_color = textures_2d[base_color_map_idx].Sample(sampler_linear_clamp, uv);
// SM 6.6+:
Texture2D<float4> base_color_map = ResourceDescriptorHeap[base_color_map_idx];
float4 base_color = base_color_map.Sample(SamplerDescriptorHeap[base_color_sampler_idx], coord);It cannot be emphasized enough how important the bindless part is. It not only makes the code clean and adds performance on the CPU side, but also opens up a lot of new cool algorithms and patterns for you to use.
Persistent data
We unload the task of processing instances and preparing the draw call from the CPU and moving it to the GPU. Because of the nature of our data and the massive parallelism available on the GPU, it seems to be a natural fit for such a task. We can allow a much higher amount of instancing processing power. Also, it solves another big problem in a classical CPU-driven pipeline: how to process instances that were generated on the GPU? When doing processing on the GPU and indirect drawing it is no longer an issue.
The scene, model, and material representations must be copied to the GPU memory to make a GPU-driven instancing pipeline work. Some people refer to it as a retained mode renderer. We store everything on the GPU and issue only a small amount of commands per frame to update data that is changed. Another added benefit: it is also beneficial for raytracing!
Let's go through the process of adding a new model that has just finished loading. Each render model is composed of LODs, that can have a hierarchy inside. Each hierarchy node can have a unique material and mesh assigned. Each material is a combination of a shader, texture, and constants.

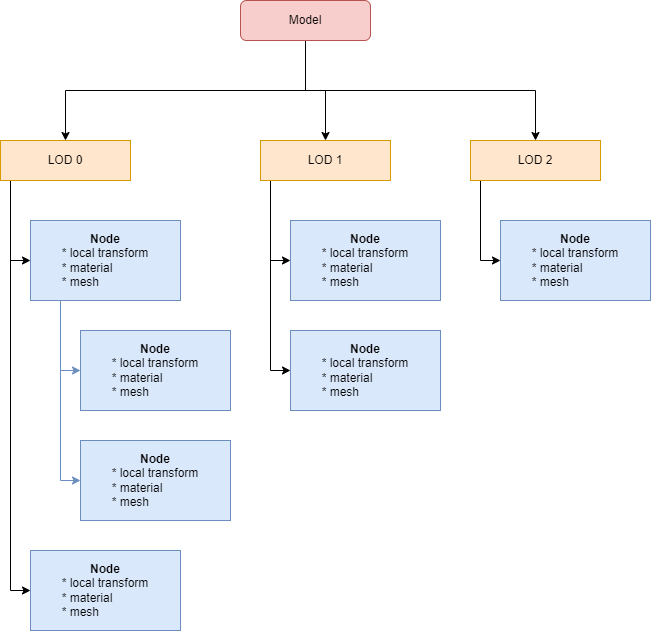
The first idea would be to upload the model to the GPU as-is and allow the compute shader to do the LOD selection. The problem with this approach is that you either will have a lot of divergency when doing the traversal in a compute shader. Or you will have to put restrictions on how your LODs and model hierarchy are arranged. We want to lift as many restrictions for Melba as possible, especially in the early stages. So that is not an option for us.
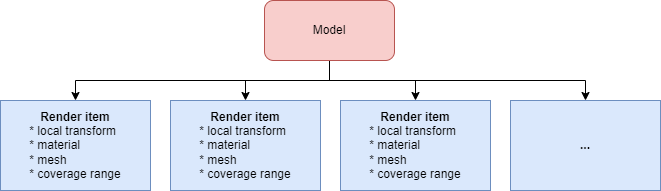
What we can do instead is to remove the concept of hierarchy altogether. Let’s flatten the hierarchy of the model and store it as a flat list of items for rendering. Sounds good, but what about LODs (they still require extra processing)? Well, we can “flatten” them as well. Let’s decompose a classical render model into a set of what we call render items.

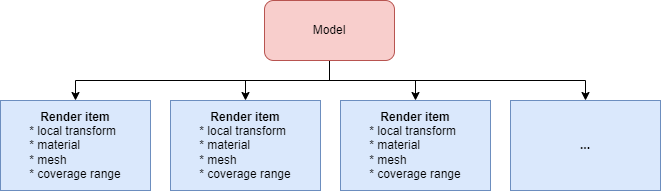
Render item - is a basic primitive of our instancing system and represents one node of a model in a specific LOD. It is a unit for the instancing system to render and has all the necessary data to render it:
struct sb_render_item_t
{
uint m_available;
// Index buffer
uint m_index_buffer_srv;
uint m_index_buffer_offset;
uint m_index_buffer_stride;
uint m_index_count;
// Geometry data
uint m_position_buffer_srv;
uint m_position_offset;
uint m_position_stride;
uint m_normal_buffer_srv;
uint m_normal_offset;
uint m_normal_stride;
uint m_uv0_buffer_srv;
uint m_uv0_offset;
uint m_uv0_stride;
// Tanget is used in the raytracing as derivatives are not available
uint m_tangent_buffer_srv;
uint m_tangent_offset;
uint m_tangent_stride;
// Material
uint m_material_buffer_srv;
uint m_material_index;
// Bounding sphere
float4 m_bounding_sphere_model_space; // (center_x, center_y, center_z, radius)
// Screen-coverage threshold
float2 m_screen_coverage_range;
// Render item transform
float4x3 m_transform;
};As mentioned earlier, we are using bindless so we can easily access all material and geometry data using 32-bit indices. Each render item can decide if it needs to be rendered independently of other render items in the same model. The whole model is expanded into a flat list of independent render items. The compute shader does not have to do any fancy traversal or indirection. It can check the visibility for a selected render item locally and also check if this LOD is visible. Metrics for selecting LODs are built in such a way that only one LOD will be selected. If morphing or dithering between the LODs is required, changing the metric will result in rendering two render items in the neighboring LODs.
We also support procedural geometry and custom render items. The system just needs to fill the material and render item structure properly and the rest will be handled by the instancing system.
Examples of the material structures:
//-----------------------------------------------------------------------------
struct sb_debug_shape_material_t
{
uint m_type;
uint m_sphere_size_in_quads;
uint m_instance_data_srv;
};
//-----------------------------------------------------------------------------
struct sb_geometry_pbr_material_t
{
float3 m_emissive_factor;
// Base color
float4 m_base_color_factor;
uint m_base_color_texture_srv;
// Metallic-Roughness
float m_metallic_factor;
float m_roughness_factor;
uint m_metallic_roughness_texture_srv;
// Normal map
uint m_normal_map_texture_srv;
// Occlusion(AO)
uint m_occlusion_texture_srv;
// Alpha
float m_alpha_cutoff;
};Material data is not stored directly in the render item but as a reference to the material buffer(shader resource view to a structured buffer and index). Render items can have arbitrary materials until it does not affect culling or LOD selection. This is how you can access the material data in the shader:
StructuredBuffer<sb_debug_shape_material_t> l_material_list = g_materials[l_render_item.m_material_buffer_srv];
l_material = l_material_list[l_render_item.m_material_index];When all materials and models are uploaded to the GPU, we are ready to start rendering something.
Instances
Our instancing system does not care about the source of the instances: they can be updated from the CPU or GPU and even from multiple sources. The only requirement is that the instance has to fill the instance description correctly:
//-----------------------------------------------------------------------------
struct sb_render_instance_t
{
float4x3 m_transform; // Transform
uint m_render_item_id; // Render item index
uint m_entity_id; // Used for selection pass
uint m_user_data; // Custom user data that can be provided per instance
float m_world_scale; // Max of (x, y, z) world scale(Used for culling)
};We have two instance buffers:
Dynamic entities are updated from the CPU in each frame.
Static entities, updated on demand when it is required. Most of the data is generated by the GPU on demand.
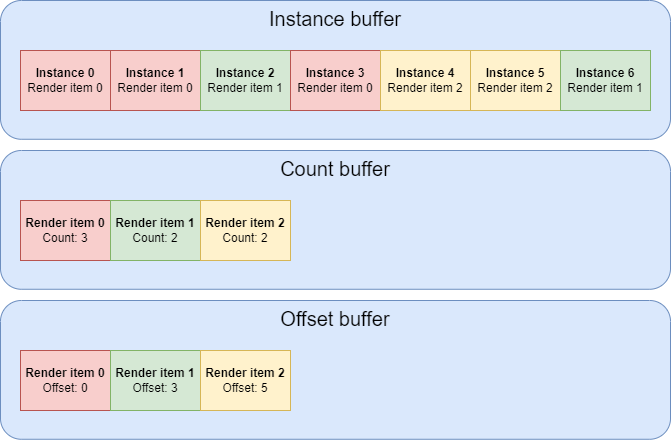
Each instance buffer has a flat list of instances. This is an example of how an instance buffer can look like(different colors represent different render items):
For the drawing, we are using execute indirect [2]. We are issuing one draw command per render item. We track state changes to make sure we minimize pipeline state switches. The command buffer is pre-filled from the CPU, with the only fields that are updated on the GPU each frame being instance count (InstanceCount) and start instance location (StartInstanceLocation).
typedef struct D3D12_DRAW_INDEXED_ARGUMENTS
{
UINT IndexCountPerInstance;
UINT InstanceCount;
UINT StartIndexLocation;
INT BaseVertexLocation;
UINT StartInstanceLocation;
} D3D12_DRAW_INDEXED_ARGUMENTS;After instancing buffers are finalized, we execute 4 compute shader dispatches:
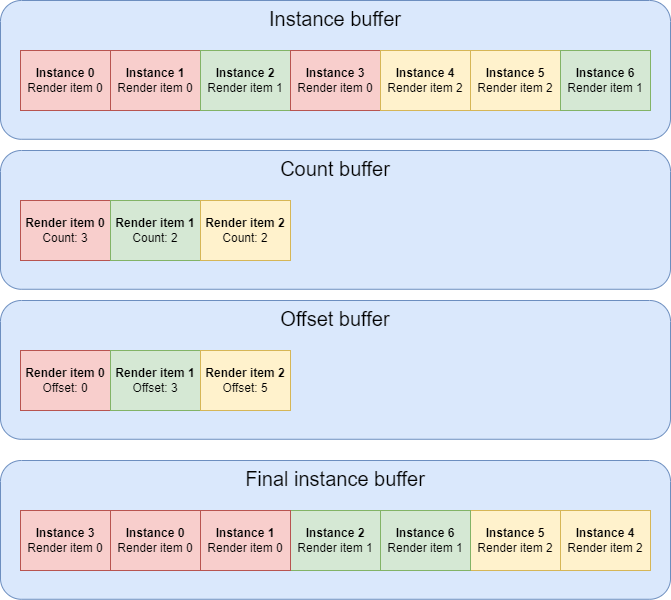
1. Clear: Resets all counters and clears structures where necessary.
2. Count: Counts visible instances per render item. This is the step where we update InstanceCount


3. Update: Computes instance offsets for each render item in the final sorted instance buffer by using the number of visible instances from the previous step. We also update StartInstanceLocation here.

4. Copy: Copies the instance data into the final instance buffer. The original ordering of the instances will not be preserved as we use atomic operations. To make it possible for custom per-instance data to be used we added m_user_data member with each instance. It can be used to index into the buffer with the custom instance data or store something in the variable itself. This is optional but is used for some render items that require additional per-instance data.

All our draw commands use the same constants as input. We use root constants to update them. The constant buffer holds the render item and renders instance meta-data:
struct cb_push_constants_t
{
uint m_render_item_buffer_srv;
uint m_render_item_index;
uint m_render_instance_buffer_srv;
uint m_render_instance_buffer_offset;
};After the instance and command buffers are filled we are ready to issue draw commands. We iterate over render items on the CPU and batch render items with the same pipelines into a single execute indirect command. Currently, we are using forward shading, so we need one draw command per render item to resolve materials and lighting in the same draw call. If a visibility buffer([3], [4]) is used, all objects can be drawn with a single command and materials will be resolved at a later stage.
Every geometry you see on the screens is rendered with our GPU-based instancing system:






Conclusion
With these simple steps, we have implemented a low-overhead CPU instancing system that can efficiently render huge amounts of instances. It can be used for different item types, including procedural or even GPU-generated content. Both CPU and GPU-generated instances are supported which fits our needs and goals of pushing more content generation to the GPU side.
Future improvements
So far we implement a small portion of what we want to get, so there is quite a long list of what we want to do
Improve multi-view support. We support rendering into multiple views. It is done by running a full pipeline for each view which is very inefficient. That is something on our list to change soon as we can process all the views during each compute dispatch.
Support passes
Cluster and triangle culling
HLODs
And much more…
References
DirectX 11 DrawIndexedInstancedIndirect
The Visibility Buffer: A Cache-Friendly Approach to Deferred Shading
