Any good engine needs to provide its users a way to view and modify run-time data. While many developers usually want as much data as possible to help them debug their work, designers often want to tinker with settings, iterating until things feel "just right". However, building a solution that works for our particular engine comes with unique challenges.
Author: Leon Lubking Senior Programmer

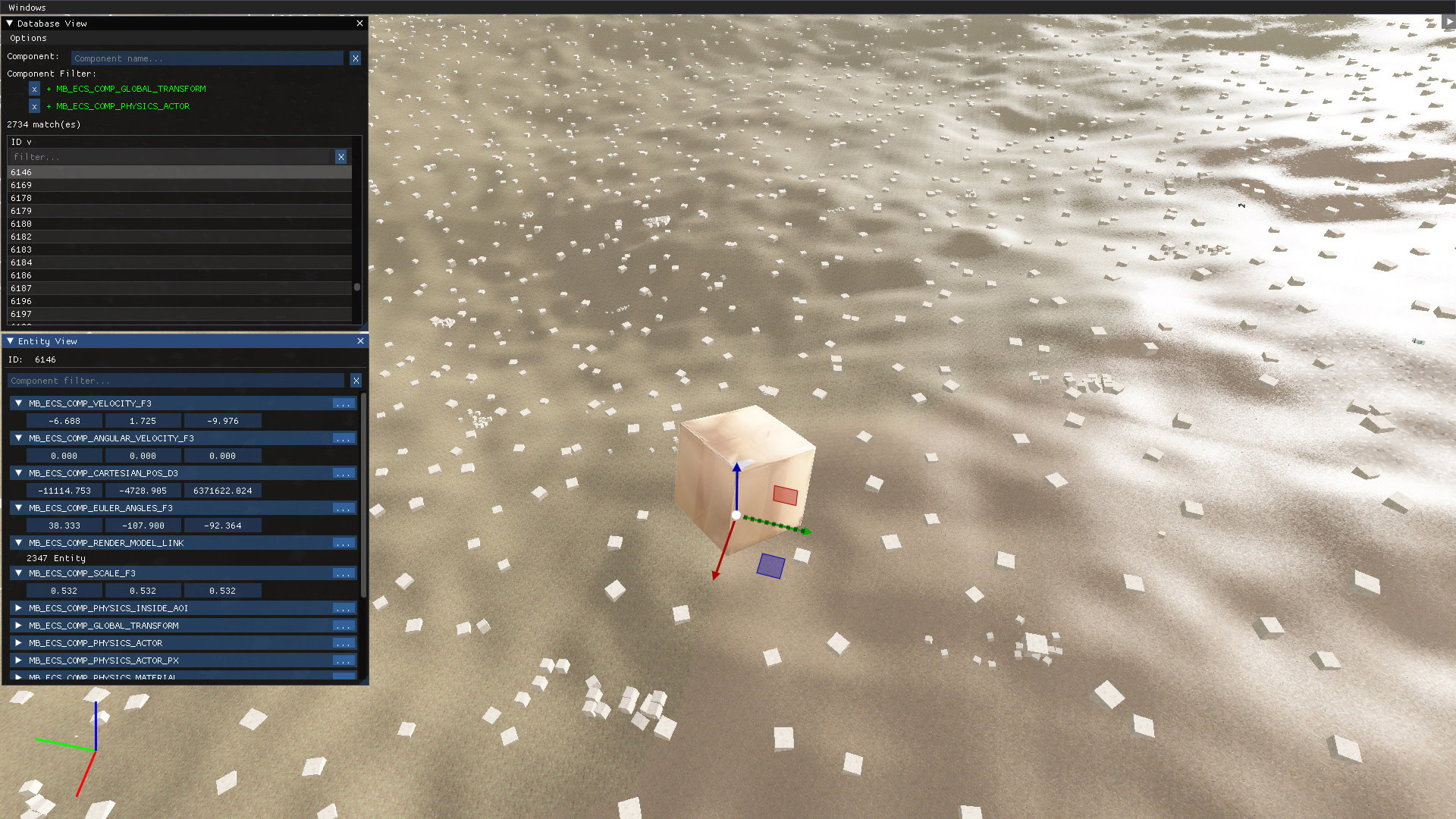
The Entity Component System defines all the individual things in our world
What does your data look like?
In Melba, we use an Entity Component System, or ECS, as the basis for all of our implementations. In addition, we favour Data-Oriented Programming paradigms over traditional Object-Oriented Programming paradigms at all times. You can refer to our earlier blog post, “Melba Philosophy and Architecture”, for more information.
The result is that we’re structuring our data in a very different way. This changes the way we visualize and edit that data.
Our basic building blocks are entities and components. An entity is just a unique index and can have 0-1 of each type of component. Components are structures with pure data—no logic, no inheritance.
You can use as many entities and components as you need to implement a feature.


A basic component
In practice, the biggest difference is that Melba does not primarily rely on hierarchies of named objects and components. Instead, it uses a huge “database” of generic entities with component data. Losing those hierarchies means that this data can look totally disorganized to the uninitiated observer. Relationships between entities, or larger concepts that any collections of entities might fit into, are not expressed directly through any easily identifiable grouping, hierarchy or name.
In other words, you don’t have a “car” object with four child “wheel” objects, you have any number of entities with all the component data that is required to implement the same functionality. The result is the same, but the entities are not named or grouped hierarchically.
This is not to say there are no hierarchies—we still need those for animation and rendering. Hierarchies, however, are not used as a default mechanism to compose and organize.
Ultimately it makes more sense to think of entities and their component data as representing a gigantic, searchable database with entities in the rows and components in the columns.
Categorization emerges from the components themselves rather than being dictated in any hierarchical way.
The entity database can be queried by our systems, which are responsible for implementing the actual logic. These systems can tell if entities are related based on their components and can process them accordingly.
What does your editor look like?
We could start with a “flat” database filled with entities and component data. Visualizing this database with typical rows and columns quickly becomes impractical since the number of entities and components can reach into the millions.
Instead, we start by allowing our editor to query the database.

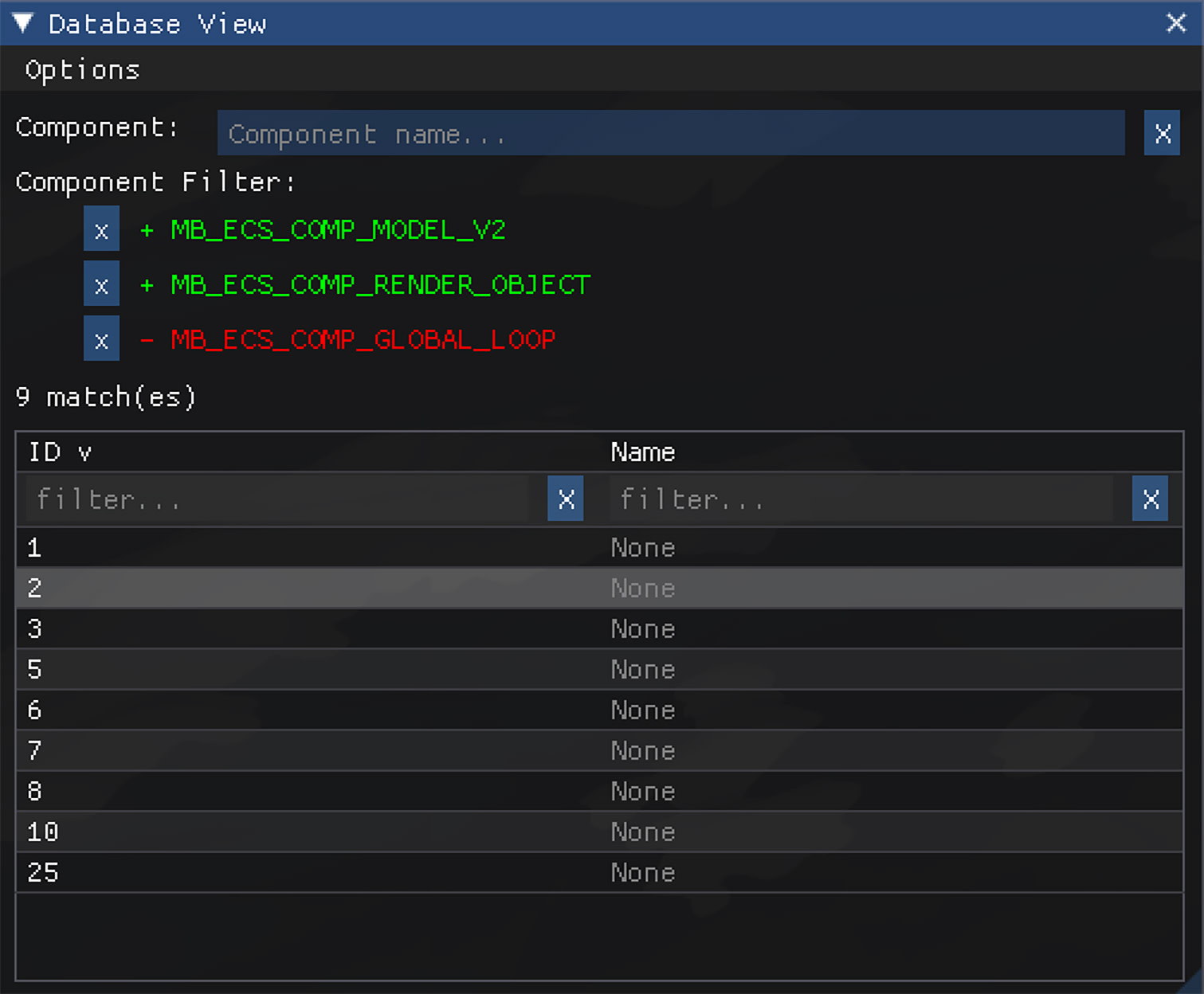
The ‘Database View’
We’ve implemented this functionality for Melba in our “Database View”. You can filter for required components, as well as components that must not be present. For example, you could query for a “mesh” component and NO “parent” component, and you would get the car body mesh entity only since the wheel meshes are children of the car body mesh.
The system allows for naming entities and filtering based on name, but this is purely a debug functionality stripped out for release builds. This is because most of what we would consider named objects in the world actually consist of any number of entities, and so the concept of “naming” an entity runs contrary to the basic structure of the data.

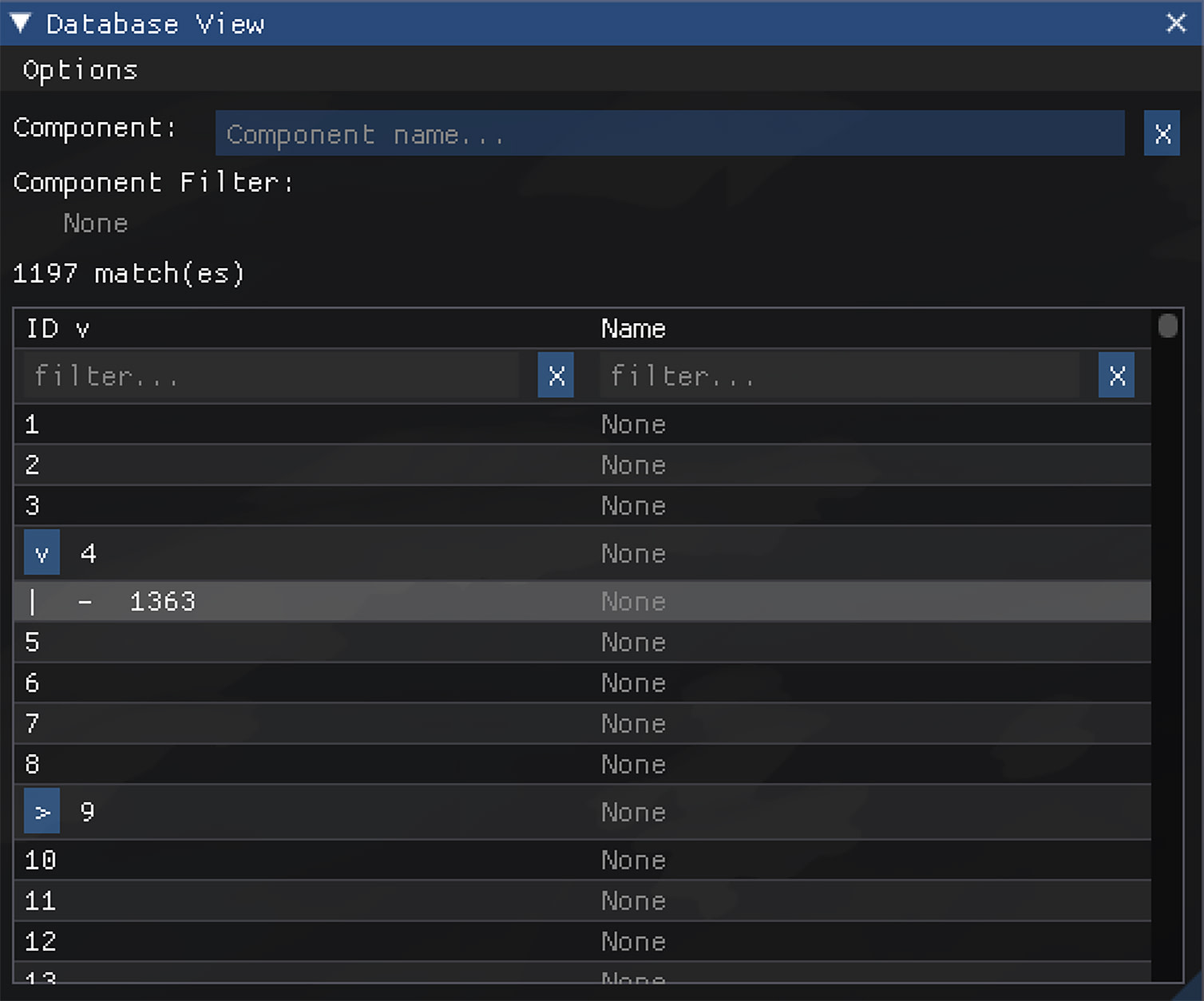
Scene-graph mode enabled
"Database View" does have an optional “scene-graph mode”, which looks for components that describe hierarchical relationships for use in rendering and animation. This looks for a "parent" component and then any "nested" entities shown underneath that parent. Scene-graph mode is similar to traditional editors, but its use is limited since we use hierarchical relationships very sparingly.
In addition to “Database View”, you can also enter “Entity View”, which allows you to select a specific entity to view its component data. “Entity View” complements “Database View” by allowing you to examine a single entity and all associated data. You can also select an entity by clicking on it in the camera viewport, provided the entity has a rendered component.

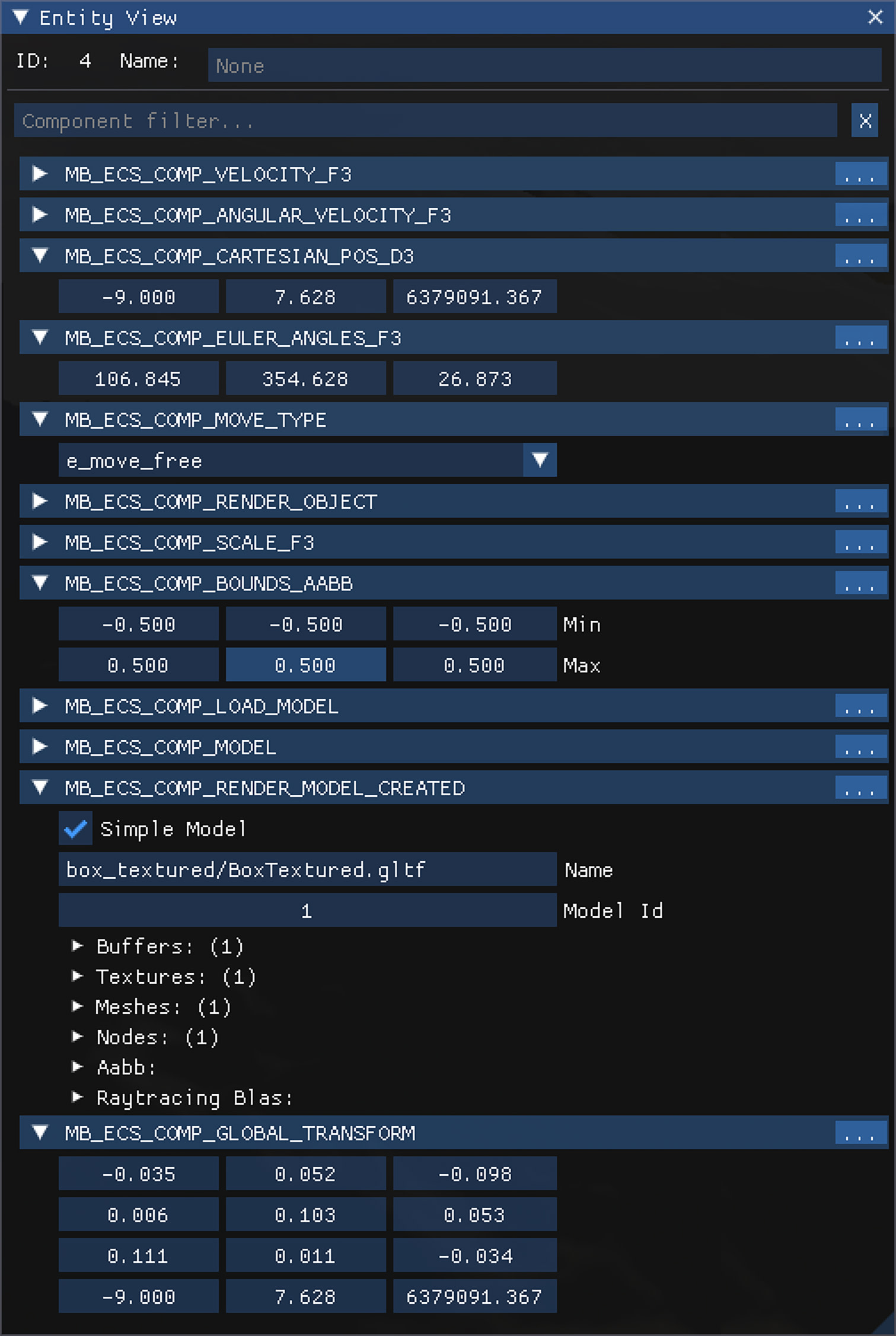
Our ‘Entity View’.
Manipulating component data
The core idea of drawing component data is that all component fields can be decomposed into primitive types like floats, integers, characters, etc. Because there are a limited number of primitive types and because we can write logic to draw each of those primitive types, this ultimately makes it possible to draw every component recursively.

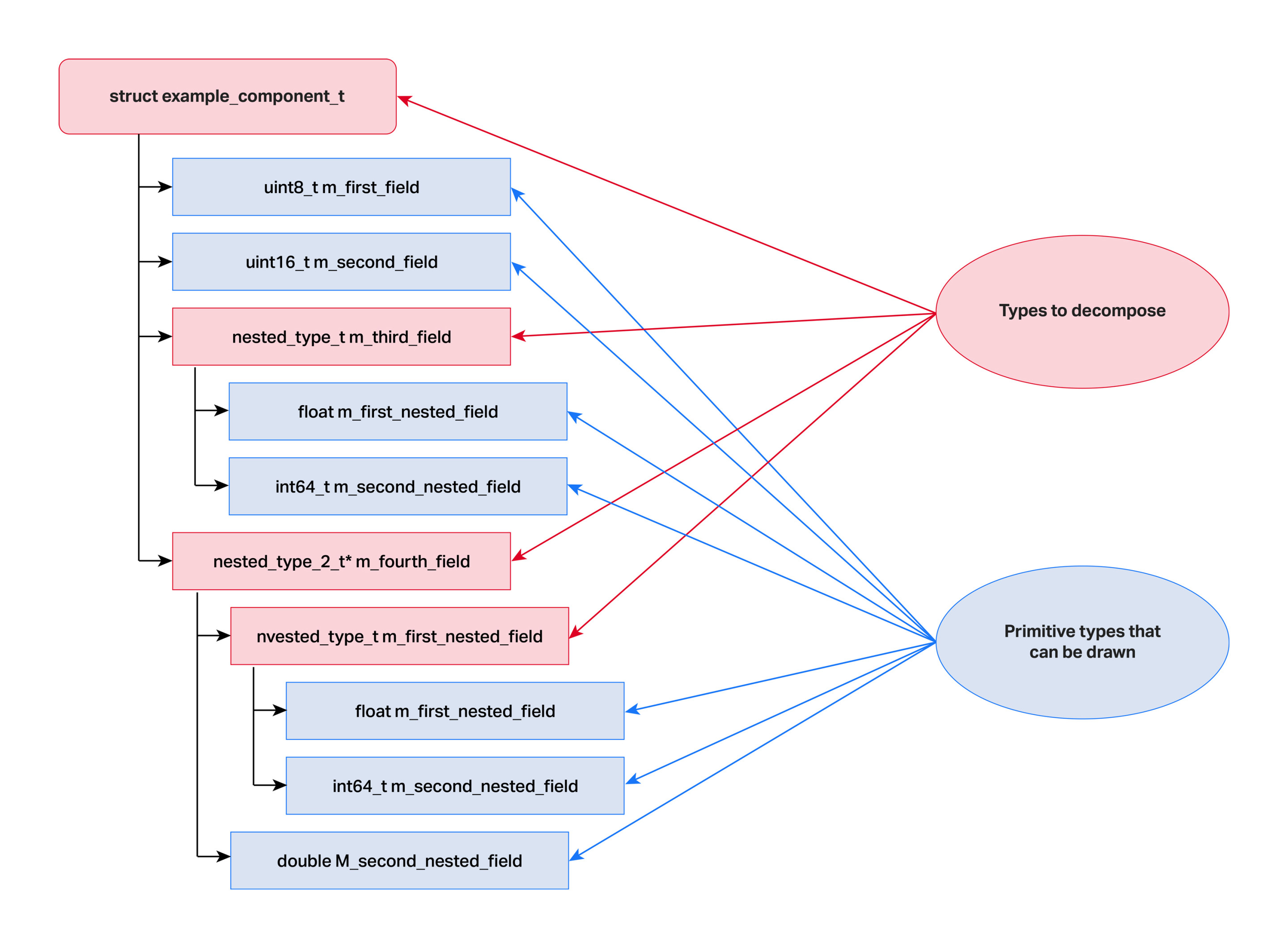
This works as long as we can provide the type information required to decompose each component field.
Implementation-wise, this is where things get complicated. We need to know all the field names, data types and memory addresses of the component fields we want to decompose.
If component fields are of a non-primitive type with nested fields, then we need the information for the nested type’s fields so we can recurse through all fields until all that is left are primitive types that we know how to draw.
What we want is a generic implementation that will work for any component ever created without having to write a lot—or any—custom code each time we add or modify a component.
To create this generic implementation, we need access to type information at run-time, but we’re using C++11, which doesn’t properly provide this.
Unfortunately, we can’t upgrade to a newer version of C++ without risking cross-platform compatibility issues. While we evaluated custom-made solutions, these tended to use newer C++ features or be overly invasive.
Viewing and editing component data is purely for debugging and authoring purposes—we don’t want it to affect the way we write our components in any significant way.
Ideally, we have something minimalistic that won’t place an undue burden on compile time and that we can easily strip out when making release builds. Type information could be delivered as a separate file and only loaded when relevant. If we can generate type information files on demand, then we can even offload the generation to some other machine or to a more opportune moment to keep our iteration times low.
Lastly, we also want to be able to view entity database dumps from other sessions for debugging. If we have type information associated with a database dump, then we should be able to view it.
Note that this means we should be able to view components without depending on the actual component type definitions being available to the code that draws the component, keeping the implementation self-contained and modular. The view implementation relies entirely on the generated type information to decompose the inspected component’s fields into more primitive types that it does know how to draw.
Our implementation
Our current implementation is a work in progress but fundamentally supports these goals. Here’s how it works at a high level:
1. Generating type information at run-time
First, each module generates the type information for its components by implementing a custom “report type information” API. Through this implementation, the programmer reports each field of each component in their module that they want to view and edit.


The window component’s struct definition


The code required to report the type information of the component and its fields using our custom API
Forgetting to report a field will simply cause it to be drawn as raw memory in hexadecimal notation. Using an incorrect name or type will fail to compile, so there isn’t much the programmer can do wrong.
Still, this is tedious busywork, so our aim is to generate this code automatically in the future.
2. Collecting type information
At startup, all type information is collected by calling all of the “report type information” method implementations for all modules.
In the future, this information could be read and written from files, so we only need to generate it once unless changes are detected.
3. Viewing and editing the components
For non-debug builds, a special module is included in the project that draws both the “Database View” and the “Entity View”.
This uses the generated type information to draw the component data and includes logic for drawing primitive types, nested types, basic collections, traversing pointers, entity references, etc.
A small problem with large consequences
We’ve had to make some compromises in this process, such as generating the information at run-time and requiring the programmer to add code to each module for each field. Ideally, the generation code should be separate and non-invasive, and we want the information to be generated offline.
These compromises stem from one annoying little problem: the memory address of a struct field cannot be known properly until that struct has been compiled.
Take the following component data structure:

Here we have a struct with fields of different sizes and a total size of 120 bytes. If we want to view this struct in our editor and modify a field, then we need to know the memory address of that field. At run-time, our ECS implementation can provide us with a pointer to the memory of the component struct. This means all we need is an offset from the memory address of the start of that struct to the field’s memory address.
You might think we could simply sum the sizes of all preceding members to calculate the memory address of the next member. Unfortunately, the compiler may apply padding and alignment to the memory layout of the struct, inserting invisible empty bytes in between fields. This process can differ based on the platform, architecture or compiler settings, so we can never be sure what has happened until after the struct has been compiled.
This means we cannot use an external process like source code analysis to determine the memory offset since the offset isn’t known until we have actually compiled the source code. Instead, we have to analyze the compiled code. The easiest way to do that is by simply running it.
When we run the compiled code, we can obtain the memory offset of a struct field by using the offsetof() macro. This is an ANSI-required macro, meaning that any ANSI standard compiler must implement it and that the macro should therefore be safe for cross-platform use.


This works, but it adds the following restrictions to our implementation:
The type information must be generated at run-time.
The code that generates the type information must refer to the struct type and the fields of that struct; therefore, it must be part of the same codebase.
The type information must be generated separately for each platform / architecture / compiler settings and for each version.
This explains how we got to our current implementation, which uses the above to generate the type information at run-time at every startup. We intend to iterate on that to make it more convenient, but fundamentally, it works.
Drawing more complex types
Our ECS components are structs with only data—no methods or inheritance are allowed. Fields are often simple primitive types but may also be a nested struct type, a fixed size array, an entity ID or a pointer.
These are all still predictable. As long as we have the required type information, we can keep digging through pointers and fields until we find primitive types that we know how to draw.
Things get more complicated when we encounter types which allocate memory dynamically and are therefore unpredictable. Even though we try to avoid it, we often use those types, for example, std::vector<>, std::map<>, etc.
If we encounter a field in which the generated type information tells us is of type td::vector<example_field_type_t>, then we need a way to find how many elements there are and how to access those elements.
We cannot simply cast the memory to std::vector<example_field_type_t> because the view implementation must be generic and has no access to the example_field_type_t type definition.
All we know is the memory address of the field, its size inside the component, name, and alleged type. We know nothing about the dynamically allocated memory it might use or how it organizes its own data internally.
We need to dig into the std::vector<> implementation to see how its memory is laid out to determine where we can find its length and how to reach each element. Adding and removing elements is even more involved. Additionally, the memory layout may differ per platform, so we need to be very careful.
For our current implementation, we managed to add support for some of these types, such as std::array<>, std::vector<>, std::shared_ptr<> and std::string, but it was a difficult and somewhat unsound process.
In the future, we may add support for more types as the need arises or re-evaluate how we support these altogether.
Annotations
A useful feature we’ve implemented is the ability to add annotations that affect how a field is drawn.


For example, you can define a minimum and maximum range for a number, make a field read-only, or display a colour picker for a float3 field instead of numbers.
Drawing methods
In addition to annotations, you can register custom drawing methods to draw a given type. If the type is encountered while recursing through the fields, then further drawing of that type is deferred to the registered method.
We are currently using ImGui, so implementing a custom drawing method can only be done in a module that includes ImGui, which is a limitation.
As with everything in our project, we may re-evaluate this in the future.
Future improvements
Flexibility and iterative design are core to the philosophy of our studio. We are, at all times, taking it step by step and re-evaluating after each one.
Our current implementation is already very useful, and in the future, we are looking into using static code analysis, code generation and build automation to remove much of the tedious busy-work that is still required.


