Building a game engine that supports earth-sized environments requires us to pay attention to the scalability of our engine. For example, the amount of data existing on the planet cannot be loaded into RAM or VRAM. Every system we design needs to take into account the assumption that data is not loaded and needs to be streamed in or in some cases even needs to be generated first.
In this blog post, we will focus on one part specifically: texture streaming. Textures are one of the most demanding aspects of game assets. For an average AAA game, textures can consume up to a hundred gigabytes of the hard drive while even a top-tier graphics processing unit (GPU) only has up to 24 GB of VRAM. In our case, it is even worse as we want to populate the whole planet.
We can’t rely on all textures being loaded into memory and need an efficient solution for texture streaming.
Author: Dmytro Pustovoitov Lead Render Programmer
Texture streaming
Let’s start with defining the term “residency”. When data is said to be "resident on GPU" it means that the data has been loaded and stored directly on the GPU. Non-resident is when the data is not present on the GPU. From a C++ perspective, you can think of it as a pointer that can be null (non-resident) or point to some data allocated on the heap (resident).
As discussed in the previous section we can’t make all our textures resident on the GPU. Furthermore, textures are only partially visible on the screen. So, only the parts required to render the current frame are required to be resident.
Let’s look at the example of the rock asset:


In this view, we don’t see the texture parts that are on the backside of the rock asset. Approximately half of the rocks' textures can be made non-resident without affecting the rendering of the current frame.
Let’s assume our rock uses three 4k textures. When compressed with BC7 each texture with a full mip-chain will consume around 22 Mb resulting in 66 Mb for this texture set. By being able to load only half of the texture data we can save 33 Mb of VRAM. The more assets will be in the camera view - the bigger the memory saving will be.
Memory savings can be even bigger when only a small portion of the texture is visible on the screen:


There are a few of obvious industry-used options for texture residence:
Texture. The texture is either fully in or fully out.
Mip. Some mips of the texture will be resident while others are not.
Tile. A region that is even smaller than a mip. For example, every 128x128 texture region can be resident or not.
While the texture and mip options are clear, let’s explain more regarding what a tile is. A tile is a region of a fixed size that is the same for all mip levels. Assume the rock’s base color texture is 512x512 and we selected the tile to be 128x128. Mip level zero will be 4x4 tiles in size, mip level one will be 2x2, and mip level two will be 1x1. Interestingly enough, we can fit all mip levels starting with level three into just one tile.


Due to the ambitious scale of our project texture and mip options don’t provide good enough scalability for use. We want to allow our artists to use as high-res textures as possible, while not limiting them on the amount of assets being used. There is a downside to the tile approach: it works best with big textures. The smaller the individual texture size gets - the less efficient memory saving becomes. Also, we will have some extra costs to maintain the streaming system based on tiles. We will discuss it in more detail in the next sections.
The approach of splitting textures into tiles and sparsely streaming the data on the GPU is commonly referred to as virtual texturing. It is called 'virtual', as we can no longer directly read texture data knowing the UV and require some form of indirection.
Virtual Texturing
The next step was to build a virtual texturing system that would cover all artist-created assets. We came up with the following requirements for our project:
Textures can be tagged as streamable or fully resident.
An artist can specify the desired minimum mip resident in memory. It is required to control the minimum fidelity desired for the specific texture.
Minimum resident mip can also be dynamically changed from the code (gameplay logic) if we need to make sure important POIs are not blurry.
There is a strict budget of memory all streaming textures should fit into.
High-level virtual texturing pipeline
Before we start using a streamable texture we need to first split it into tiles. It makes sense to make all tiles of the same pixel size. It is done to simplify the streaming logic and budgeting as every tile will have the same exact size and dimension for every mip of every texture. By default, textures will be initialized as having no resident tiles as we don’t know what parts of them are visible.
These steps can be illustrated with a diagram:

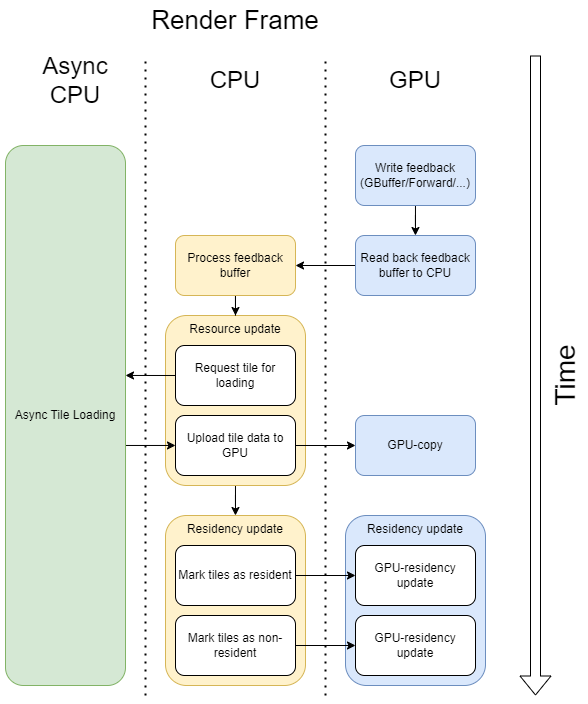
Let’s have a look at each individual step:
Write feedback while rendering a frame using virtual textures. Feedback is information that describes which resource tiles were requested by the rendering pipelines. It is needed so we can determine later what data needs to be streamed in and what needs to be streamed out.
After the render frame is finished, read back the feedback buffer. We don’t want this to be a blocking operation, so double or triple buffering will be required depending on how many frames in flight your engine allows.
When readback is ready we can process the feedback buffer on the CPU.
Assemble the list of the tiles that need to be loaded from disk and request async loading.
If the data is loaded, copy it to the GPU. This most likely will require double or triple buffering.
Go through the list of the tiles that are being loaded from the disk.
Mark tiles as residents if they are non-resident and the tile’s data has finished uploading to the GPU.
Mark tiles non-resident if they are no longer used on the GPU. If the tile has a queued loading request and no longer needs to be resident - cancel the loading operation. This most likely will require double or triple buffering.
This is a very high-level overview, but it should give enough information on what steps are required to integrate virtual texturing into your engine.
Hardware-specific features
The next step is to look into what technologies and features from the rendering APIs can be used to simplify or improve the implementation of our virtual texturing system. Virtual texturing can be fully implemented on the software level, but why not check if there is something that can help us?
Melba is a DX12-level engine. We intend to support multiple platforms, but our min-spec is DX12-level systems. For simplicity, I will operate with DX12 terminology, but a parallel can be drawn with other APIs.
These are three features in particular that our virtual texturing system can benefit from:
Reserved (a.k.a. tiled) resources
Sampler feedback
DirectStorage
There is not so much information on the internet on those features and almost nothing on using them for virtual texturing.
Reserved resources
The usual approach for implementing tiles and partial residence is to create a tile pool (that is shared for all textures) and per-texture indirection buffer. The tile pool can be a texture atlas or a texture array and will hold the texture data. When we want to sample a texture at a certain UV, we follow the indirection into the tile pool and sample the tile there. Due to DirectX limitations, a pool per texture type will be created which makes budgeting harder. Things are even more complex when using anisotropic filtering. Shared borders need to be implemented for each tile and sometimes even manual filtering schemes.
Reserved resources are quite old and supported since DX11. The DX11 feature was called “tiled resources” and was renamed in DX12. This feature allows resources to be partially resident. That is exactly what we need for splitting the texture into tiles and allowing them to be partially resident. It works as follows: the texture is split into tiles of a fixed size (64Kb in DX12). Every tile can be resident or non-resident. To make a tile resident, we need to provide space in a heap that will hold the tile’s data. After updating we mark the tile as a resident through an API call.
Reserved resources have quite a lot of advantages:
All texture types are supported. The tile is a fixed size and format-agnostic. That means the same heap can hold tiles of different types. No more restrictions on texture types. We also don’t need to do specific per-format pools/atlases and can have one budget
Texture filtering is handled on the hardware. We can use all hardware filtering modes without the need to implement filters manually or introduce tile borders.
Of course, the approach comes with a set of disadvantages:
Tile residency can be changed only from the CPU. We cannot use GPU to update resident state which is the limiting factor for using GPU-driven pipelines.
For us, the advantages outweigh the disadvantages. However, we would want to have an API to do residency updates from the HLSL code.
This feature was not used that much due to the simple fact that the performance was not great for all vendors. There is almost no information regarding the current state available over the Internet, so we did a benchmark prototype in our engine to see if it is still the case. We tested reserved resources on different scenes for three scenarios:
Regular. All textures are regular.
Reserved+Resident. All textures are reserved resources. All tiles are resident.
Reserved+Checkerboard. All textures are reserved resources. Tiles are resident with a checkerboard pattern for every texture.
Here you can see the average frame time in different scenes. The difference in timings between regular and reserved resources is surprisingly small compared to the benefit of the reserved resources. All scenes were tested with alpha-tested objects present and maximum anisotropy filtering forced. So it will provide a higher frame time impact than a regular game scene.

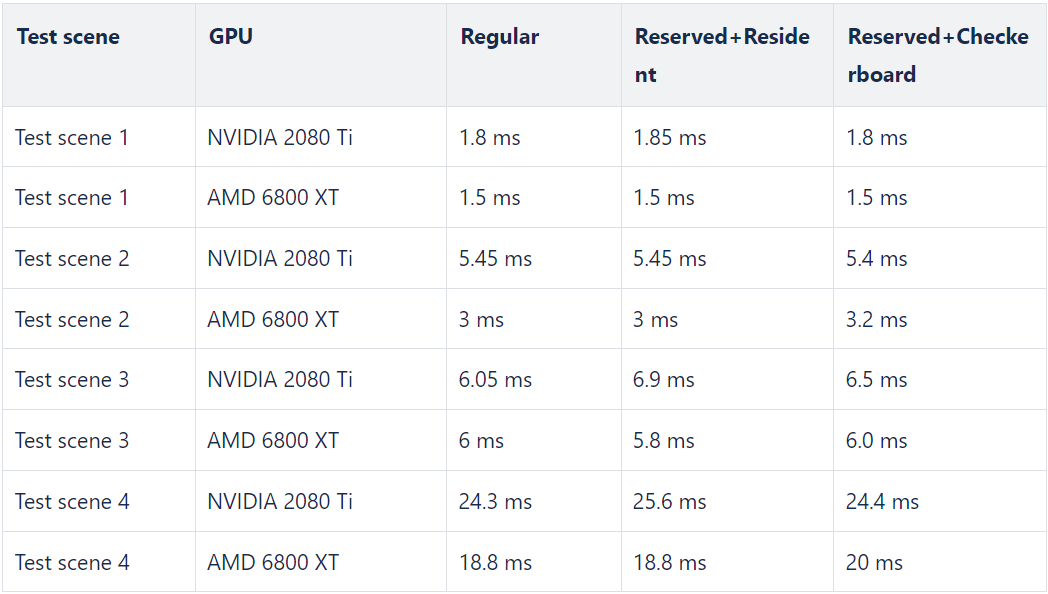
Important note: we have not tested AMD RDNA 1 and earlier architectures as those cards do have a perf problem with reserved resources. For us, this is not an issue, as our engine is targeted for future generations of hardware. If your min-spec is RDNA2 and onward - feel free to start using reserved resources. It is always nice when hardware support for features improves.
Sampler feedback This is a feature that allows us to write a feedback buffer. The feedback buffer will contain which tiles were requested during rendering. The biggest benefit of this approach is that we don’t need to build analytical approximations on which tiles were sampled.
Sampler feedback can be used in two different ways: MIN_MIP and MIP_REGION. If you intend to use it for virtual texturing you want to use MIN_MIP. You want to have one feedback pixel for every tile. Then for every tile, you will get a minimum mip value that was requested for the tile. By processing the map you can determine which tiles to load and which to evict. DX12 has some limitations on the feedback texture size, so in some cases, your tile will be covered and you will need to process multiple feedback pixels per tile:
for(uint32_t l_y = 0; l_y < m_height_in_tiles; ++l_y)
{
for(uint32_t l_x = 0; l_x < m_width_in_tiles; ++l_x)
{
// Scan all feedback pixels that cover current tile
uint8_t l_requested_mip = 0xFF;
for(uint32_t l_feedback_x = l_x * l_tile_size_in_feedback_pixels_x; l_feedback_x < (l_x + 1) * l_tile_size_in_feedback_pixels_x; ++l_feedback_x)
{
for(uint32_t l_feedback_y = l_y * l_tile_size_in_feedback_pixels_y; l_feedback_y < (l_y + 1) * l_tile_size_in_feedback_pixels_y; ++l_feedback_y)
{
l_requested_mip = std::min(l_requested_mip, p_tiled_resource.m_min_mip_requested[m_sampler_feedback_width * l_feedback_y + l_feedback_x]);
}
}
}
}The feature is very useful but comes with a similar issue as the reserved resources: performance. The hardware implementation was not great which resulted in poor performance. On NVIDIA the feature performs well while there were problems on AMD and Intel. Luckily for us, both vendors improved the design on the latest hardware architectures (AMD RDNA 2/3, NVIDIA Ampere, Intel Alchemist). The only important part to take into account is not to write sampler feedback for every pixel. That’s quite easy to implement by writing one pixel in every 4x4 pixel block and shifting the pixel position every frame.
// Write sampler feedback before a possible early exit
// Some vendors recommend doing it stochastically(AMD, NVIDIA)
#if defined(MB_VIRTUAL_TEXTURE_WRITE_FEEDBACK)
// Improvement: we can make this animated, but so far no artifacts are seen from using a static pattern
// 4x4 seems to be granular enough
if( p_screen_xy.x % 4 == 0 &&
p_screen_xy.y % 4 == 0)
{
l_feedback_texture.WriteSamplerFeedback(l_texture, p_sampler, p_uv);
}
#endifDirectStorage A recent addition that allows faster streaming of data from the hard drive. Depending on the platform and vendor even direct streaming into GPU memory is possible, which significantly improves streaming speed. It is specifically optimized to handle huge amounts of small-sized data chunksand perfectly matches our texture tiles. Due to higher priority features, DirectStorage was postponed for later iterations, so we won’t cover this topic now.
Optimizations As described in the previous section we decided to use the following features:
Reserved resources
Sampler feedback
It is important to understand that these features are not required to implement virtual texturing. It is quite easy to replace them with software implementations, but to save some time and get a couple of nice extra benefits we decided to go this way. Performance will not be affected on our target hardware.
An important optimization we implemented is to not write sampler feedback for every streamable texture every frame. The number of textures can get quite big and there will still be a delay in streaming data from the hard drive or SSD. What we do instead is select a small number of textures per frame that will be used for sampler feedback. The number is configurable and allows us to amortize the added performance cost for the sampler feedback.
Another part that has not been covered yet is how we track the available pages on the GPU. For that, we keep a GPU buffer that holds the minimal mip available for every tile. Before reading the texture we fetch the minimal mip available value from that buffer and use a HLSL instruction to tell the sampler to clamp the mip usage:
// Get min mip from residency buffer
int2 l_uv_int = frac(p_uv) * p_residency_buffer_dim;
uint l_residency_buffer_index = l_uv_int.y * p_residency_buffer_dim.x + l_uv_int.x;
uint l_min_mip_level = l_residency_map.Load(l_residency_buffer_index);
// Sample texture
float4 l_color = l_texture.Sample(p_sampler, p_uv, 0, l_min_mip_level);Conclusion
We ended up with a flexible and easy-to-maintain virtual texturing solution. By using advanced hardware features we were able to implement it quickly and got some extra benefits along the way. Utilizing this system will allow us to remain scalable to earth-sized environments while keeping our texture budgets under control.
Currently, our assets consume 70-80% less texture memory on the GPU due to the implementation of virtual texturing. Those numbers include additional memory costs like indirection textures, feedback buffers, and readback buffers. Memory savings will become even better the more assets we use.
It is important to emphasize, that there is no solution that fits all. You need to carefully weigh all your requirements and pick a solution that works best for you.
Future improvements
It is only the first iteration of the virtual texturing system and we intend to improve it a lot further:
Include DirectStorage. That should greatly improve texture streaming speed.
Procedural virtual texturing. For complex materials we want the heavy computations to be done in a lazy manner and cached into virtual texture tiles.
Software implementation to unlock GPU-driven passes. We want to also implement a software solution instead of sparse textures to fully unlock our GPU-driven pipeline.
Resources
